Consequences of Data Representation on Programming
Data representation has important consequences for designing and writing
accurate and reliable programs. Some major issues involve:
For example, conditional statements may yield unexpected
results, loops may not terminate as planned, and computations may
accumulate numerical errors.
Note: Most of the floating-point examples in this reading involve
float type, since float numbers store only 7-8 digits of
accuracy, and the corresponding examples utilize relatively modest-sized
numbers. The same issues arise for double numbers. However,
since double numbers store 16 or so digits of accuracy, examples
typically involve relatively long sequences of digits and thus may seem
somewhat unintuitive.
Integer overflow
The Reading on
the Binary Representation of Integers observed that most programming
languages, including C, allocate a specified number of bits for the
storage of an integer.
-
In relatively early computers, 16 bits were allocated to an integer. Thus,
signed integers could be in the range -32768 to 32767, and unsigned
integers could be in the range 0 through 65535.
-
Many modern computers allocate 32 bits for an integer. With this
allocation, signed integers can be in the range -2,147,483,648 to
2,147,483,647, and unsigned integers can have the range 0 through
4,294,967,295.
-
Some recent computers allocate 64 or more bits, with even larger ranges for
signed and unsigned integers.
Whatever the number of bits allocated, integer storage has two essential
properties:
Processing that attempts to compute and/or store an integer outside the
limited range yields a condition called overflow. Hardware
sometimes raises error conditions that can be investigated when overflow
occurs — but sometimes processing continues with numbers that may have
little meaning.
Examples:
Two examples may highlight some of the difficulties that can arise from
integer overflow.
Example 1: Computing an Average
Consider the following program average-2-ints.c that is designed to read two
integers and compute their average:
/* program to average two numbers */
#include <stdio.h>
int main ()
{
int num1, num2;
printf ("Enter two integers: ");
scanf ("%d%d", &num1, &num2);
int avg = (num1 + num2) / 2;
printf ("The average of the numbers is %d\n", avg);
return 0;
}
This program was run twice on a machine utilizing 32-bit integers, yielding
the following two results:
Enter two integers: 3 5
The average of the numbers is 4
Enter two integers: 2000000000 2000000000
The average of the numbers is -147483648
The first run produces the expected value: 4 is indeed the average of 3
and 5.
However, the second run reports that the average of two positive
numbers is negative. The issue is that the sum 2000000000 + 2000000000 is
4000000000 — a number larger than the 2,147,483,647 maximum for
signed integers on a 32-bit machine. In this case, 4000000000 is
interpreted as a negative number, and this number divided by 2 is still
negative.
Caution:
When applications utilize integer data, programmers must anticipate the
potential size of the integers. Integer overflow can have devastating
consequences.
Example 2: Comair
In December 2004, Comair, an airline with a hub in Cincinnati, Ohio,
utilized a database system that included a table for schedule changes.
Data recorded included both flights and flight crews. In the evolution of
the software system, each change in the table was numbered sequentially
starting at 1 and using 16-bit signed integers. After the new year, the
airline had planned to upgrade the system to a 32-bit numbering system, but
this change in software was deferred until after the busy holiday season.
Unfortunately, the Midwestern United States experienced many storms
throughout December 2004, leading to many schedule changes for both flights
and crews for the approximately 1100 flights that Comair flew daily.
The underlying software system kept up with these changes until the number
of changes reached 32768 — just beyond the limit for 16-bit signed
integers. At that point, the computer system crashed, and Comair had to
cancel all of its flights on December 25, 2004. News reports indicated
that some 30,000 travelers in 118 cities were affected.
Floating-point overflow, underflow, and round-off error
Just as integer values may be too large or too small to be stored in the
space allocated for an int, real numbers may be outside the range
that can be stored by a float or double. Recall
from the Reading on
the Binary Representation of Floating-Point Numbers that real numbers
are stored in a scientific notation, including a mantissa and an exponent.
-
Floating-point overflow arises when the required exponent for a
floating-point number is larger than the space available.
-
Floating-point underflow arises when the required exponent for a
floating-point number too small to be stored.
For float numbers, exponents of two normally must be between -126
and 127, although some adjustments are allowed for positive numbers smaller
than 2-126. When the scientific notation yields
2128 or larger, then the number cannot be stored in a
float and floating-point overflow occurs. A similar statement
applies to underflow.
A different type of issue arises for floating-point numbers, because only
23 bits (single precision) or 52 bit (double precision) are available to
store a mantissa. Whenever a mantissa requires additional storage, the
number cannot be stored exactly, and an error, called roundoff
error, arises.
Perhaps surprisingly,
inherent round-off error has a direct impact on the properties of addition,
as illustrated by a short computation.
Rather than computing with binary numbers and storing 23 or 52 bits of
accuracy, consider the analogous problem of storing decimal numbers with 4
digits of accuracy. When considering 1.000 + 0.0007, the result should be
1.0007. However, only 4 digits of accuracy can be stored, so a choice is
needed.
-
1.0007 might be truncated to 1.000
-
1.0007 might be rounded to 1.001
Although either approach is possible, the addition algorithm should be
consistent.
Now consider the sum 1.000 + 0.0007 + 0.0007. The specific computation
depends upon where parentheses are inserted. Additional may arise,
depending upon whether truncation or rounding is used to maintain 4-digits
of storage.
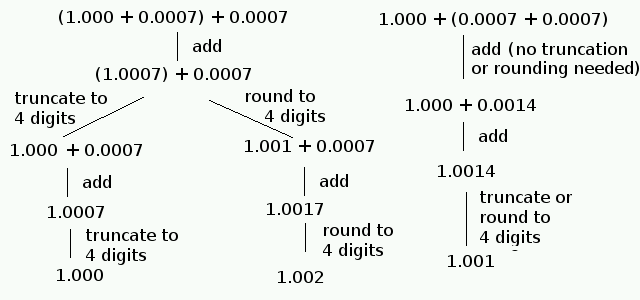
In summary:
-
Left associativity with truncating for (1.000 + 0.0007) + 0.0007 produces
1.000 as the arithmetic result.
-
Left associativity with rounding for (1.000 + 0.0007) + 0.0007 produces
1.002 as the arithmetic result.
-
Right associativity with truncating or rounding for 1.000 + (0.0007 +
0.0007) produces 1.001 as the arithmetic result.
Conclusion: Regardless of whether truncation or rounding is used,
left associativity produces a different result than right associativity.
That is, addition within the computer is not associative, so many
familiar properties of numbers no longer hold!
Example 3: One tenth (decimal)
The Reading on
the Binary Representation of Floating-Point Numbers determined that the
decimal, floating-point number 1/10 has an infinite binary representation:
0.000110011001100110011... . Since this number would require infinite
storage, the decimal number 1/10 cannot be stored exactly within either
single-precision or double-precision storage. Thus, the actual storage of
this number contains some error (small, but non-zero0).
Example 4: The Vancouver Stock Exchange Index
Although the roundoff error for an individual number may be small, such
errors can accumulate when a computer repeats the same process thousands,
millions, or billions of times. The following example is taken from The
Limits of Computer by Henry M. Walker, Jones and Bartlett Publishers,
pp. 100-101, and is used with permission of the copyright holder.
Between 1981 and 1983, the Vancouver Stock Exchange Index was computed with
each trade of stock. The computation used four decimal places in the
computation, but the result was then truncated to three places of
accuracy. This computation was then repeated with each of the
approximately 3000 trades that occurred daily. As a result of the
truncation of the calculation to three decimal places, the index lost
about 1 point a day, or about 20 points per month. Thus, to correct this
consistent numerical error, the index was recomputed and corrected over the
weekend of November 26, 1983. Specifically, when trading concluding on
November 25, the Vancouver Stock Exchange Index was quoted as 524.811; the
corrected figure used to open Monday morning was 1098.892. The correction
for 22 months of compounded error caused the Index to increase by 574.081
over a weekend without any changes in stock prices. In this example,
computations began with correct data, but subsequent processing introduced
a significant error in the result.
Floating-point comparisons in if statements
Since real numbers are stored with the potential for round-off error, the
actual number stored may be slightly smaller or slightly larger than the
intended number. Thus, comparisons with real numbers should take small
errors into account.
Example 5 illustrates some difficulties that can arise.
-
In Example 5, the decimal number 0.1 (one tenth) is added ten times, with
the intention of achieving the number 1.0. However, when double
the value stored for one tenth is slightly smaller than the intended value,
due to round off. Adding this number several times yields
0.9999999999999999, a number very close to 1.00, but not the same. As a
result, a test for equality between the sum and 1.0 fails.
-
When Example 5 is changed, so that all numbers are of type float
rather than type double the printed sum is 1.0000001192092896
— a number slightly larger than 1.0. In this case, the value stored
for one tenth is slighter larger than the intended value.
When testing real numbers, these examples illustrate that some adjustment
may be needed to allow for round-off error. For example, a test
if (result == one)
might be adjusted as follows:
double allowed_error = 0.01;
if ((result > one - allowed_error) && (result < one + allowed_error))
Example 5:
Consider the following program one-tenth.c that adds the decimal number 0.1 (one tenth)
to itself:
/* Program to compute 0.1 + 0.1 + ... 0.1 (ten times) */
#include <stdio.h>
int main ()
{
double one = 1.0;
double ten = 10.0;
double one_tenth = one / ten;
double result = one_tenth + one_tenth + one_tenth
+ one_tenth + one_tenth + one_tenth
+ one_tenth + one_tenth + one_tenth
+ one_tenth;
printf ("result is %20.16lf\n", result);
if (result == one)
printf ("adding one_tenth ten times IS one\n");
else
printf ("adding one_tenth ten times IS NOT one\n");
return 0;
}
This program adds one_tenth 10 times and produces the following output:
result is 0.9999999999999999
adding one_tenth ten times IS NOT one
Altogether, the storage 1.0/10.0 (decimal) includes a small round-off
error. Adding the number 10 times yields a number quite close to 1.0, but
not exactly 1.0.
Floating-point comparisons in loops
The same issues of round-off errors arise in loops as in comparisons. For
loops, such errors may impact the number of times the body of a loop is
executed. Example 6 illustrates one type of difficulty.
-
Example 6 contains a loop in which the control variable val starts
at 0.0 and is supposed to be incremented by one tenth until the value 1.0 is
achieved. However, since the loop condition tests for equality of real
numbers, the two numbers are never exactly the same, and the loop continues
for a very long time.
A somewhat more subtle difficulty arises if the loop in Example 6 is
changed, with the intention that the values to be added are 0.0, 0.1, 0.2,
..., 0.9, 1.0. One candidate for the loop condition might be
while (val <= end)
However, a careful reading of the output from Example 6 shows that the
computer would produce the following output within the loop.
val = 0.000000000000000; sum = 0.000000000000000
val = 0.100000001490116; sum = 0.100000001490116
val = 0.200000002980232; sum = 0.300000011920929
val = 0.300000011920929; sum = 0.600000023841858
val = 0.400000005960464; sum = 1.000000000000000
val = 0.500000000000000; sum = 1.500000000000000
val = 0.600000023841858; sum = 2.099999904632568
val = 0.700000047683716; sum = 2.799999952316284
val = 0.800000071525574; sum = 3.599999904632568
val = 0.900000095367432; sum = 4.500000000000000
Although the intention was for the computer to execute the loop with
val having the value 1.0, the next value of val would be
1.000000119209290, a value larger than 1.0, and the loop terminates one
iteration early.
As illustrated above, one way to address this problem involves including an
allowed-error term:
double allowed_error = 0.01;
while (val <= end + allowed_error)
However, this approach would be adding 0.1 to val several times,
and we know the value 0.1 is not stored exactly. Thus, each iteration of
the loop would be including additional round-off error to our results. To
avoid this problem, one might use an integer variable to control the loop.
int i;
for (i = 0; i <= 10; i++)
{
val = i / 10.0;
...
In this approach, the int variable is stored exactly, and the loop
guarantees that the loop will be executed the proper number of times.
Further, the value of val is recomputed from exact numbers with
each iteration. Storage of the resulting real number in val may
involve round-off error. However, the round-off error in val will
not accumulate from iteration to iteration, since the computation for
val begins fresh each time.
Example 6: Loop until equality condition
Consider the task of start at 0.0 and adding 0.1, 0.2, 0.3, 0.4, ... until
the number being added is 1.0. The program float-loop.c performs this task
using float numbers throughout.
/* Program to study a loop with floats */
#include <stdio.h>
int main ()
{
float inc = 1.0/10.0;
float val = 0.0;
float end = 1.0;
float sum = 0.0;
printf ("program to loop with floats from %22.15f to %22.15f increment %22.15f\n",
val, end, inc);
while (val != end)
{
/* add to sum and print */
sum += val;
printf ("val = %22.15f; sum = %22.15f\n", val, sum);
/* increment val for loop test and next iteration */
val += inc;
}
printf ("loop terminated with val = %22.15f; sum = %22.15f\n", val, sum);
}
When this program is run, the first part of the output begins
program to loop with floats from 0.000000000000000 to 1.000000000000000 increment 0.100000001490116
val = 0.000000000000000; sum = 0.000000000000000
val = 0.100000001490116; sum = 0.100000001490116
val = 0.200000002980232; sum = 0.300000011920929
val = 0.300000011920929; sum = 0.600000023841858
val = 0.400000005960464; sum = 1.000000000000000
val = 0.500000000000000; sum = 1.500000000000000
val = 0.600000023841858; sum = 2.099999904632568
val = 0.700000047683716; sum = 2.799999952316284
val = 0.800000071525574; sum = 3.599999904632568
val = 0.900000095367432; sum = 4.500000000000000
val = 1.000000119209290; sum = 5.500000000000000
val = 1.100000143051147; sum = 6.600000381469727
val = 1.200000166893005; sum = 7.800000667572021
val = 1.300000190734863; sum = 9.100000381469727
val = 1.400000214576721; sum = 10.500000953674316
val = 1.500000238418579; sum = 12.000000953674316
val = 1.600000262260437; sum = 13.600001335144043
val = 1.700000286102295; sum = 15.300001144409180
val = 1.800000309944153; sum = 17.100002288818359
val = 1.900000333786011; sum = 19.000001907348633
As this output indicates, the value being added never is exactly 1.00.
The value being added does reach 1.000000119209290, a value very close to
1.00, but not exactly the same. As a result, this program continues in an
apparent infinite loop.
Interestingly, although the numbers are slightly different, the same issue
arises if all variables have type double rather than type
float.
Error accumulation
Since the number of bits available to store real numbers is limited, the
storage of any floating-point number is subject to some round-off error.
Although the amount of error for an individual number may be quite small,
these numbers may be used in loops that continue for thousands, millions,
billions or more iterations. As a result, round off errors can accumulate.
-
In the Vancouver Stock Exchange Index example (Example 4), each computation
was stored to three decimal places, with an error of no more than 1 in the
third decimal place (an error no more than 0.001). However, such
computations were made about 3000 times per day for 22 months. At the end
of that time, the computed value was 524.811, and it turned out that the
accumulated error was 574.081 — the error was larger than the
computed value!
-
In Example 6, 0.1 was added repeated to a val variable.
Initially, the print out showed round-off error in the 9th decimal place.
However, with each iteration, the amount of error increased. By the
seventh iteration (with val being 0.600000023841858), a small
round-off error appeared in the 8th decimal place. By the 20th iteration
(with val being 1.900000333786011), the error in the 8th decimal
place was noticeably larger.
Although such accumulated error may have little significance for some
applications and computations, the level of inaccuracy may matter
significantly in other circumstances. Although a full analysis of accuracy
is well beyond the scope of this course, three notes seem appropriate.
-
Whenever floating-point numbers are involved in computations, questions
should be asked regarding accuracy. How accurate are the results, and how
do you know?
-
The initial discussion of round-off error (near Example 4) considered the
sum 1.000 + 0.0007 + 0.0007.
-
In this example, using the large number (1.000) first had the effect of
overwhelming the small numbers (0.0007). More generally, adding very small
floating-point numbers to large ones may not be noticeable — the
addition may be lost in bits that cannot be stored.
-
Adding small numbers first may allow the sums to accumulate (e.g., 0.0007
+ 0.0007 = 0.0014), and the result may be large enough to impact the
addition of large numbers.
Overall, a program should add small numbers together before adding the sum
to larger numbers; adding numbers in ascending order can be a helpful
strategy.
-
The mathematical subject, called numerical analysis, explores the
accumulation of numerical error in substantial depth. When an application
requires considerable accuracy, investigation of techniques from numerical
analysis may be particularly important.
created 3 June 2016 by Henry M. Walker
expanded and edited 4 June 2016 by Henry M. Walker
|


|
|
For more information, please contact
at
.
|