-
To investigate the storage of double numbers, the program pi-storage.c prints the number Pi to several decimal places of accuracy.
Download, compile, and run this program.
- How does the program store and print the value of Pi exactly to 39 decimal places of accuracy? That is, how are the 39 digits stored and printed exactly?
- The output of the program is organized into groups of lines. Describe what is printed on each line of a group. Also, indicate how each output line is obtained. (You may need to consult a C/C++ manual to understand some functions, such as sprint.)
- printf tries to round a double to the number of decimal places specified. For the output involving 13 to 16 decimal places, does the output reflect this rounding?
- What can you say about rounding (or the lack thereof), when 17 or more decimal places are printed?
- As the number of digits are printed (after 17 decimal places), what can you say about the accuracy of the double number printed? Why do you think this accuracy is (or is not) observed?
Associativity of Addition for Real Numbers
Over the years, many approaches have been developed to compute the value of the number π. Many of these approaches are based on an infinite series, one of which is
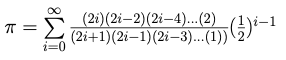
Details behind this formula may be found in a Wikipedia article on Leibniz formula for π and a stockexchange article on Series that converge to π quickly.
Although this is an infinite sum, calculus (and algebra) indicates that successively better approximations to π may be obtained by including more and more terms of the series. Also, it is worth noting that computationally each term is smaller than the previous.
Program pi-approx.c
- asks the user how many terms n in the series to compute,
- computes the desired number of terms,
- computes and prints the sum, starting from term i=0 to i=n-1 (that is, starting with the largest term and adding successive smaller terms), and also
- computes and prints the sum, starting from term i=n-1 to i=0 (that is, starting with the smallest term and adding successive larger terms).
-
Download, compile, and run program pi-approx.c
- In reading the program, how are successive terms in the series computed—explain briefly why this approach gives the desired sum of terms.
- Describe the output generated with the number of terms being 10, 25, 40, 50, 60, 100, and 1000.
- To what extent does including more terms to the sum help the accuracy when computing from the largest term to the smallest? Explain.
- To what extent does including more terms to the sum help the accuracy when computing from the smallest term to the largest? Explain.
- If there is a difference when computing from largest term to smallest versus smallest term to largest, explain the difference. What, if any, conclusions are suggested by the outputs observed from this exercise?
Compounding of Numeric Error
Our discussions of the representation of real numbers (doubles and floats) have identified at least three factors that can cause errors in processing—particularly if the errors can accumulate as processing continues.
- numerical errors can accumulate in some situations, as processing continues (particularly in loops that are repeated many times,
- loops may not continue through the proper number of iterations,
- the order of addition can make a difference:
- if small numbers are added to large ones, the small numbers may be lost
- if small numbers are added together first and then to large ones, then the small values may have an impact in the overall sum
Be sure to take these potential troubles into account in answering Steps 4 and 5.
-
Given that
start < end, suppose a loop is to begin atstartand finish at (or near)endin exactlyn+1iterations. Within this loop, suppose the control variable will increase by a computed valueincrement = (end-start)/nwith each iteration.Two loop structures are proposed:
// approach 1 increment = (end - start)/n; for (i = 0; i <= n; i++){ value = start + i * increment; /* processing for value */ }// approach 2 value = start; increment = (end - start)/n; while (value <= end) { /* processing for value */ value += increment; }Although the first approach requires somewhat more arithmetic within the loop than the second, it likely will provide better accuracy. Identify two distinct reasons why the first approach should be preferred over the second.
-
Suppose
y = f(x)is a function that decreases significantly fromx=atox=b, on the interval[a, b], witha < b.Throughout this interval, assume
f(x)>0, and assume the Trapezoidal Rule were to be used to approximate the area undery = f(x)on the interval[a, b].-
Assuming accuracy is the highest priority for this computation, should the main loop begin at
aand go towardbor begin atband go towarda, or is either order fine? Explain. -
Again, assuming accuracy of the answer is the highest priority, write a reasonably efficient code that implements the Trapezoidal Rule for this function on this interval. (To be reasonably efficient, f(x) should be computed only once for each value of x, and division by 2 should be done as little as possible, as discussed in class.)
Be sure to include your code within a program, and run several tests of the program.
For this step, submit both the program and the output from several test runs.
(Of course, your program must conform to the course's C/C++ Style Guide.) -
Explain how and why your approach to this problem (with
f(x)decreasing significantly fromx=atox=b) should be different from the code whenf(x)increases over this interval.
-
