| CS 415, Section 001 | Sonoma State University | Fall, 2022 |
|
Algorithm Analysis
|
||
|
Instructor: Henry M. Walker
Lecturer, Sonoma State University | ||
Although much of this course is well developed, some details can be
expected to evolve as the semester progresses.
Any changes in course details will be announced promptly during class.
This worksheet/lab is in three parts: brute force algorithms, Merge Sort and heaps.
This section on contains two exercises related to brute force algorithms.
As discussed in class, a permutation sort uses the following basic algorithm, given an array A of size n:
Various sources indicate that the permutation sort has
O((n-1)!), O(n!), and/or O((n!)*n), where ! is the factorial
operator (so 4! = 4*3*2*1)
Which, if any, of these conclusions is correct? Briefly
justify your answer.
Note: This problem asks for a logical argument and
conclusion, NOT code to perform the permutation sort.
In class, we discussed
program list-processing.c, which
included a recursive printReverseRecursive
procedure that uses recursion to print a linked list in reverse
order. For example, given the list
"Node A" "Node B" "Node C" "Node D" "Node E"
the procedure prints
"Node E" "Node D" "Node C" "Node B" "Node A"
However, the list is not formatted, with parentheses around
the entire list and the list nodes separated by commas, such
as
("Node E", "Node D", "Node C", "Node B", "Node A")
Program list-processing.c contains a stub for a new
procedure printReverseRecursiveFormatted.
Complete this procedure, so that the resulting code
recursively prints a formatted result of the nodes in reverse
order, as described above.
printReverseRecursive.
This section on Merge Sort asks you to compare two implementations of a Merge Sort, following the approaches to timing you followed in the Worksheet/Lab on the Quicksort [and other topics].
As with the quicksort-comparisons.c program, your program should check that the sorted merge sort procedures produce properly sorted arrays and report the time required for sorting for various sized data sets.
For this exercise, submit a full listing of your program (Doxygen output output not required, although the code must follow the course's C++ Style Guide).
Run the program on data sets that have different sizes. For each size, run the procedures on data that have ascending, random, and descending order.
This section is divided into
A max-heap is a binary tree with the property that the value at each node is larger (according to some ordering) than the values stored in either child. Similarly, a min-heap is a binary tree with the property that the value at each node is smaller (according to some ordering) than the values stored in either child.
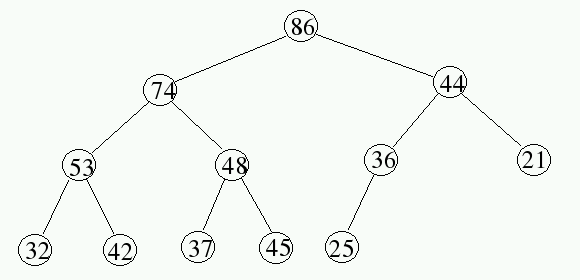
Further, we restrict our attention to trees which are completely balanced. All nodes have 2 children, except at the bottom of the tree. The last row of the tree may not be full, but any items on the last level are moved left as much as possible. For example, the following tree illustrates the shape of a tree and the ordering of values within the tree for a max-heap.
To identify the nodes in a tree, the simplest approach is to number the nodes level-by-level from the root downward. Within a level, nodes are numbered left to right. Also, for simplicity, many textbooks assign the index 1 to the root node.
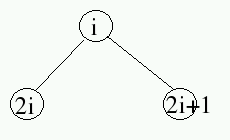
In examining the label nodes, a pattern emerges: for each node labeled i, the left child has label 2*i and the right node has label 2*i+1.
Note: As previously noted, some textbooks, such as Data Structures and Problem Solving Using Java, Fourth Edition by Mark Allen Weiss. uses this numbering scheme in writing code, with the top node numbered 1. If one considers an array element 0, Weiss suggests filling that position with -∞ for a min-heap or ∞ for a max-heap.
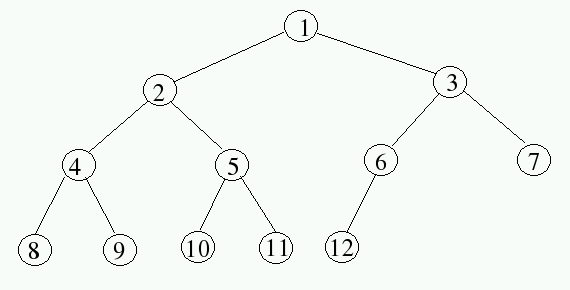
If we start labeling at 0 rather than 1, the labeling of nodes becomes:
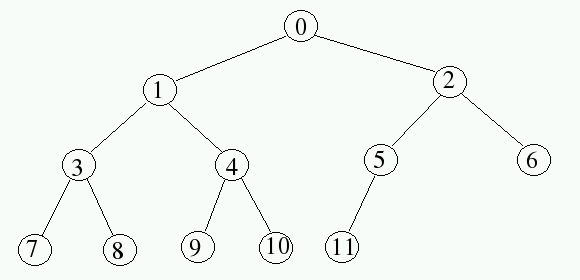
In the context of 0-based labeling, identify a pattern for moving from a node with label j to its left child and its right child. What labels would be found on the left and right nodes of a node with label j?
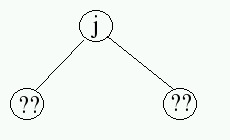
Since nodes in a heap fit a straight forward identification system, there is a natural mapping between the logical nodes in a heap and the indexed elements of an array.
In class we considered how to insert an item into a heap and maintain the structure. In each case, we first place the item at the end of a tree (as far left as possible in the last row). The item then is worked up from its position, until the data in the tree are appropriately ordered.
The following heap repeats the structure given at the beginning of this lab:
Using this structure as a start, insert the values 30, 25, 55, 81, and 95. Show the structure of the tree and the values in each node after each insertion.
In class, we also considered how to remove the top-priority item from a heap: remove the root as the item to be returned, move the last item from the end of the heap to the root, and work that item down in the heap until the data are properly ordered.
In class, we discussed starting with an array of data and working from the bottom toward the top to rearrange the data to yield a heap. In the following problem, consider working with a min-heap.
In the following questions, consider a heap implemented with 0-based indexing.
Suppose an array of twelve elements, a[12], is initialized with a[i] = 20-i for each i. What rearrangements, if any, need to be done in order to make the corresponding tree structure into a heap? Show the data in the array once a heap is achieved.
Suppose the array of twelve elements, a[12], is initialized with a[i] = i for each i. What rearrangements, if any, need to be done in order to make the corresponding tree structure into a heap? Show the data in the array once a heap is achieved.
|
created December 1, 2018 revised December 2, 2018 revised December 27-30, 2021 revised February 4, 2022 reformatted and heap material added July 28, 2022 reorganized with brute force/merge sort added October 3-6, 2022 |
|
| For more information, please contact Henry M. Walker at walker@cs.grinnell.edu. |

|
Copyright © 2011-2022
by Henry M. Walker.
|